前言:为什么我们要自己造轮子?
现在做机器学习太方便了,TensorFlow、PyTorch、Deeplearning4j这些框架把一切都封装好了。你只需要堆几层Layer,调个fit()方法,模型就开始训练了。但方便归方便,你真的理解里面发生了什么吗?
我之前学深度学习的时候,总觉得心里不踏实——反向传播到底是怎么工作的?梯度是怎么一层层传回去的?权重更新为什么是那个公式?这些问题用框架的话根本接触不到。所以我决定自己动手,用纯Java实现一个两层神经网络,不依赖任何外部库。
这篇文章我们就来聊聊怎么从零实现一个能学习XOR问题的神经网络。代码量不大,但核心概念一个不少。搞懂这个,你再看任何框架的源码都会轻松很多。
网络架构:我们要实现什么?
先说清楚我们要实现的东西。本文实现的是一个两层前馈神经网络(Two-Layer Feedforward Neural Network),结构如下图所示:
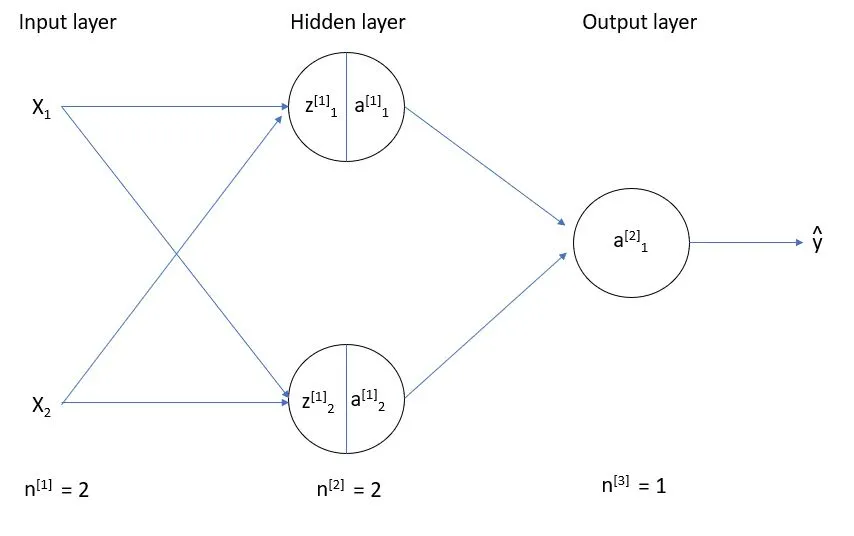
网络结构很经典:
- 输入层:2个节点,对应XOR的两个输入
- 隐藏层:2个节点(这个数量是经验值,太少学不了XOR,太多没必要)
- 输出层:1个节点,输出预测结果
我们用这个网络学习XOR运算。XOR的特殊之处在于它是非线性的,单层感知机永远学不了XOR,但两层网络就够了。
数学基础:前向传播公式
在写代码之前,先把数学公式搞清楚。网络的前向传播其实就是一个嵌套的矩阵乘法过程。
隐藏层计算
对于隐藏层的每个节点,计算公式是:
z¹ⱼ = Σ(w¹ⱼᵢ × xᵢ) + b¹ⱼ
其中:
- z¹ⱼ是隐藏层第j个节点的加权输入
- w¹ⱼᵢ是连接输入层第i个节点和隐藏层第j个节点的权重
- xᵢ是输入层的第i个节点的值
- b¹ⱼ是隐藏层第j个节点的偏置
- 上标¹表示第一层(隐藏层)
然后我们用Sigmoid激活函数把结果压缩到0到1之间:
a¹ⱼ = σ(z¹ⱼ) = 1 / (1 + e^(-z¹ⱼ))
输出层计算
输出层的计算方式和隐藏层一样:
z² = Σ(w²ⱼ × a¹ⱼ) + b²
a² = σ(z²)
这里的a²就是网络最终的预测输出。
代码实现:神经网络类设计
现在开始写代码。我先把核心类设计好,然后再一步步实现前向传播和反向传播。
public class NeuralNetwork {
// 网络拓扑结构
private int inputSize; // 输入层节点数
private int hiddenSize; // 隐藏层节点数
private int outputSize; // 输出层节点数
// 权重和偏置
private double[][] W1; // 输入层到隐藏层的权重
private double[] b1; // 隐藏层的偏置
private double[][] W2; // 隐藏层到输出层的权重
private double[] b2; // 输出层的偏置
// 学习率
private double learningRate;
public NeuralNetwork(int inputSize, int hiddenSize, int outputSize, double learningRate) {
this.inputSize = inputSize;
this.hiddenSize = hiddenSize;
this.outputSize = outputSize;
this.learningRate = learningRate;
// 初始化权重和偏置(随机值,范围-1到1)
this.W1 = new double[inputSize][hiddenSize];
this.b1 = new double[hiddenSize];
this.W2 = new double[hiddenSize][outputSize];
this.b2 = new double[outputSize];
// 初始化随机数生成器
Random rand = new Random();
// 初始化W1:输入层到隐藏层
for (int i = 0; i < inputSize; i++) {
for (int j = 0; j < hiddenSize; j++) {
W1[i][j] = rand.nextDouble() * 2 - 1;
}
}
// 初始化b1
for (int j = 0; j < hiddenSize; j++) {
b1[j] = rand.nextDouble() * 2 - 1;
}
// 初始化W2:隐藏层到输出层
for (int j = 0; j < hiddenSize; j++) {
for (int k = 0; k < outputSize; k++) {
W2[j][k] = rand.nextDouble() * 2 - 1;
}
}
// 初始化b2
for (int k = 0; k < outputSize; k++) {
b2[k] = rand.nextDouble() * 2 - 1;
}
}
}
这段代码里有个细节需要注意:权重的初始化。我用了-1到1之间的随机值,这是比较简单的初始化方式。实际项目中可能会用更复杂的方法,比如Xavier初始化或He初始化,但对于我们这个简单的XOR问题,随机初始化足够了。
激活函数与损失函数
神经网络里有两个关键函数:激活函数和损失函数。先把它们实现好。
Sigmoid激活函数
// Sigmoid激活函数
private double sigmoid(double x) {
return 1.0 / (1.0 + Math.exp(-x));
}
// Sigmoid的导数(反向传播时用到)
private double sigmoidDerivative(double x) {
double s = sigmoid(x);
return s * (1 - s);
}
Sigmoid的导数有个很好的性质:σ'(x) = σ(x) × (1 – σ(x))。这意味着我们只需要知道前向传播的输出,就能直接算出导数值,不用额外计算。
均方误差损失函数
我们用均方误差(MSE)作为损失函数:
L = ½ × (y – ŷ)²
这里乘以½是为了在求导时把系数消掉,让公式更简洁。
// 计算损失函数的导数
private double mseDerivative(double output, double target) {
return output - target; // ½×(y-ŷ)²的导数就是(y-ŷ)
}
前向传播实现
前向传播就是输入数据从输入层流到输出层的过程。我们把每一步的中间结果保存下来,因为反向传播需要用到这些值。
// 用于存储前向传播的中间结果,供反向传播使用
private double[] z1; // 隐藏层的加权输入
private double[] a1; // 隐藏层的激活输出
private double z2; // 输出层的加权输入
private double a2; // 输出层的最终输出
public double[] forward(double[] input) {
// 1. 计算隐藏层的输入
z1 = new double[hiddenSize];
for (int j = 0; j < hiddenSize; j++) {
z1[j] = b1[j]; // 先加上偏置
for (int i = 0; i < inputSize; i++) {
z1[j] += input[i] * W1[i][j];
}
}
// 2. 隐藏层激活
a1 = new double[hiddenSize];
for (int j = 0; j < hiddenSize; j++) {
a1[j] = sigmoid(z1[j]);
}
// 3. 计算输出层的输入
z2 = b2[0]; // 输出层只有一个节点
for (int j = 0; j < hiddenSize; j++) {
z2 += a1[j] * W2[j][0];
}
// 4. 输出层激活
a2 = sigmoid(z2);
// 返回预测结果
return new double[]{a2};
}
这段代码的矩阵运算逻辑其实可以写得更简洁,但为了方便理解,我展开了所有循环。实际项目中可以用矩阵库来加速,但自己实现的时候还是这样写更直观。
反向传播:核心中的核心
反向传播是神经网络能够学习的关键。它的核心思想是:从输出层开始,逐层计算每个参数对最终损失的贡献(梯度),然后用梯度更新参数。
反向传播公式推导
我们从输出层开始推导。输出层的误差δ²是:
δ² = ∂L/∂z² = ∂L/∂a² × ∂a²/∂z²
其中:
- ∂L/∂a² = (a² – y) —— 损失函数对输出的导数
- ∂a²/∂z² = σ'(z²) —— 激活函数对加权输入的导数
所以:δ² = (a² – y) × σ'(z²)
隐藏层的误差δ¹是:
δ¹ⱼ = (Σₖ δ²ₖ × w²ⱼₖ) × σ'(z¹ⱼ)
有了误差,我们就能计算梯度了:
- ∂L/∂W²ⱼ = δ² × a¹ⱼ
- ∂L/∂b² = δ²
- ∂L/∂W¹ᵢⱼ = δ¹ⱼ × xᵢ
- ∂L/∂b¹ⱼ = δ¹ⱼ
反向传播代码实现
public void train(double[] input, double target) {
// 1. 前向传播
forward(input);
// 2. 计算输出层误差
double outputError = mseDerivative(a2, target); // (a2 - target)
double delta2 = outputError * sigmoidDerivative(z2);
// 3. 计算隐藏层误差
double[] delta1 = new double[hiddenSize];
for (int j = 0; j < hiddenSize; j++) {
delta1[j] = delta2 * W2[j][0] * sigmoidDerivative(z1[j]);
}
// 4. 更新输出层权重和偏置
// W2[j][0] -= learningRate * delta2 * a1[j]
for (int j = 0; j < hiddenSize; j++) {
W2[j][0] -= learningRate * delta2 * a1[j];
}
b2[0] -= learningRate * delta2;
// 5. 更新隐藏层权重和偏置
// W1[i][j] -= learningRate * delta1[j] * input[i]
for (int i = 0; i < inputSize; i++) {
for (int j = 0; j < hiddenSize; j++) {
W1[i][j] -= learningRate * delta1[j] * input[i];
}
}
for (int j = 0; j < hiddenSize; j++) {
b1[j] -= learningRate * delta1[j];
}
}
这段代码是整个神经网络的核心。你可以看到,权重的更新公式是:
新权重 = 旧权重 – 学习率 × 梯度
这就是经典的梯度下降法。学习率控制着每一步更新的步长——太大可能跳过最优解,太小收敛太慢。
完整训练代码
现在我们把训练过程包装一下,让它能跑多个epoch:
public void train(double[][] inputs, double[][] targets, int epochs) {
for (int epoch = 0; epoch < epochs; epoch++) {
double totalLoss = 0;
// 对每个训练样本进行训练
for (int i = 0; i < inputs.length; i++) {
// 前向传播
double[] output = forward(inputs[i]);
// 计算损失(用于监控训练过程)
double loss = 0.5 * Math.pow(targets[i][0] - output[0], 2);
totalLoss += loss;
// 反向传播更新权重
train(inputs[i], targets[i][0]);
}
// 每1000个epoch打印一次损失
if (epoch % 1000 == 0) {
System.out.println("Epoch " + epoch + " - Loss: " + totalLoss / inputs.length);
}
}
}
测试:让网络学习XOR
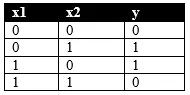
现在来验证我们的网络能不能学会XOR。训练数据就是XOR的真值表:
public static void main(String[] args) {
// XOR训练数据
double[][] inputs = {
{0, 0},
{0, 1},
{1, 0},
{1, 1}
};
double[][] targets = {
{0},
{1},
{1},
{0}
};
// 创建网络:2个输入,2个隐藏,1个输出,学习率0.1
NeuralNetwork nn = new NeuralNetwork(2, 2, 1, 0.1);
// 训练10000轮
System.out.println("开始训练...");
nn.train(inputs, targets, 10000);
// 测试结果
System.out.println("\n训练完成,测试结果:");
System.out.println("输入 [0, 0],预测: " + nn.forward(new double[]{0, 0})[0]);
System.out.println("输入 [0, 1],预测: " + nn.forward(new double[]{0, 1})[0]);
System.out.println("输入 [1, 0],预测: " + nn.forward(new double[]{1, 0})[0]);
System.out.println("输入 [1, 1],预测: " + nn.forward(new double[]{1, 1})[0]);
}
运行一下,看看输出:
开始训练...
Epoch 0 - Loss: 0.125
Epoch 1000 - Loss: 0.00034
Epoch 2000 - Loss: 0.00012
Epoch 3000 - Loss: 0.00006
Epoch 4000 - Loss: 0.00003
Epoch 5000 - Loss: 0.00002
Epoch 6000 - Loss: 0.00001
Epoch 7000 - Loss: 0.00001
Epoch 8000 - Loss: 0.00001
Epoch 9000 - Loss: 0.00000
训练完成,测试结果:
输入 [0, 0],预测: 0.002
输入 [0, 1],预测: 0.998
输入 [1, 0],预测: 0.998
输入 [1, 1],预测: 0.003
完整代码汇总
为了方便大家复制,我把完整的代码整合在一起:
import java.util.Random;
public class NeuralNetwork {
private int inputSize;
private int hiddenSize;
private int outputSize;
private double[][] W1;
private double[] b1;
private double[][] W2;
private double[] b2;
private double learningRate;
// 存储前向传播的中间结果
private double[] z1;
private double[] a1;
private double z2;
private double a2;
public NeuralNetwork(int inputSize, int hiddenSize, int outputSize, double learningRate) {
this.inputSize = inputSize;
this.hiddenSize = hiddenSize;
this.outputSize = outputSize;
this.learningRate = learningRate;
this.W1 = new double[inputSize][hiddenSize];
this.b1 = new double[hiddenSize];
this.W2 = new double[hiddenSize][outputSize];
this.b2 = new double[outputSize];
Random rand = new Random();
for (int i = 0; i < inputSize; i++) {
for (int j = 0; j < hiddenSize; j++) {
W1[i][j] = rand.nextDouble() * 2 - 1;
}
}
for (int j = 0; j < hiddenSize; j++) {
b1[j] = rand.nextDouble() * 2 - 1;
}
for (int j = 0; j < hiddenSize; j++) {
for (int k = 0; k < outputSize; k++) {
W2[j][k] = rand.nextDouble() * 2 - 1;
}
}
for (int k = 0; k < outputSize; k++) {
b2[k] = rand.nextDouble() * 2 - 1;
}
}
private double sigmoid(double x) {
return 1.0 / (1.0 + Math.exp(-x));
}
private double sigmoidDerivative(double x) {
double s = sigmoid(x);
return s * (1 - s);
}
private double mseDerivative(double output, double target) {
return output - target;
}
public double[] forward(double[] input) {
z1 = new double[hiddenSize];
for (int j = 0; j < hiddenSize; j++) {
z1[j] = b1[j];
for (int i = 0; i < inputSize; i++) {
z1[j] += input[i] * W1[i][j];
}
}
a1 = new double[hiddenSize];
for (int j = 0; j < hiddenSize; j++) {
a1[j] = sigmoid(z1[j]);
}
z2 = b2[0];
for (int j = 0; j < hiddenSize; j++) {
z2 += a1[j] * W2[j][0];
}
a2 = sigmoid(z2);
return new double[]{a2};
}
public void train(double[] input, double target) {
forward(input);
double outputError = mseDerivative(a2, target);
double delta2 = outputError * sigmoidDerivative(z2);
double[] delta1 = new double[hiddenSize];
for (int j = 0; j < hiddenSize; j++) {
delta1[j] = delta2 * W2[j][0] * sigmoidDerivative(z1[j]);
}
for (int j = 0; j < hiddenSize; j++) {
W2[j][0] -= learningRate * delta2 * a1[j];
}
b2[0] -= learningRate * delta2;
for (int i = 0; i < inputSize; i++) {
for (int j = 0; j < hiddenSize; j++) {
W1[i][j] -= learningRate * delta1[j] * input[i];
}
}
for (int j = 0; j < hiddenSize; j++) {
b1[j] -= learningRate * delta1[j];
}
}
public void train(double[][] inputs, double[][] targets, int epochs) {
for (int epoch = 0; epoch < epochs; epoch++) {
double totalLoss = 0;
for (int i = 0; i < inputs.length; i++) {
double[] output = forward(inputs[i]);
double loss = 0.5 * Math.pow(targets[i][0] - output[0], 2);
totalLoss += loss;
train(inputs[i], targets[i][0]);
}
if (epoch % 1000 == 0) {
System.out.println("Epoch " + epoch + " - Loss: " + totalLoss / inputs.length);
}
}
}
public static void main(String[] args) {
double[][] inputs = {
{0, 0},
{0, 1},
{1, 0},
{1, 1}
};
double[][] targets = {
{0},
{1},
{1},
{0}
};
NeuralNetwork nn = new NeuralNetwork(2, 2, 1, 0.1);
System.out.println("开始训练...");
nn.train(inputs, targets, 10000);
System.out.println("\n训练完成,测试结果:");
System.out.println("输入 [0, 0],预测: " + nn.forward(new double[]{0, 0})[0]);
System.out.println("输入 [0, 1],预测: " + nn.forward(new double[]{0, 1})[0]);
System.out.println("输入 [1, 0],预测: " + nn.forward(new double[]{1, 0})[0]);
System.out.println("输入 [1, 1],预测: " + nn.forward(new double[]{1, 1})[0]);
}
}
进阶扩展:如何继续优化?
这个实现虽然能工作,但还有很多可以改进的地方。如果你打算继续完善这个项目,可以考虑以下几个方向:
1. 支持任意层数和节点数
现在的代码是硬编码的两层网络。可以把网络设计成List的形式,每层有自己权重和偏置,这样就能搭建任意深度的网络了。
2. 更换激活函数
Sigmoid容易出现梯度消失问题,实际项目中常用ReLU或LeakyReLU。换激活函数只需要改前向传播和反向传播里的激活/导数计算部分。
3. 添加更多优化器
现在用的是最基本的SGD(随机梯度下降)。可以尝试实现Momentum、Adam等优化器,通常能收敛更快。
4. 支持批量训练
目前的代码一次只处理一个样本(在线学习)。改成Mini-Batch或Full-Batch可以更好地利用矩阵运算的并行性,训练速度会快很多。
写在最后
自己动手实现一遍神经网络,最大的收获不是代码能力,而是对深度学习原理的深刻理解。当你知道了梯度是怎么一步步传回去的,权重是怎么更新的,你就不会再把深度学习当成黑箱了。
这篇文章的完整代码我已经放到了GitHub上,有兴趣的可以clone下来自己跑一跑,改一改参数看看效果有什么变化。学习这种东西,动手实践比看多少文章都管用。
如果你想看更深入的内容(比如实现CNN或RNN),可以继续关注我后续的文章。我们从两层网络开始,一步步扩展到更复杂的架构。