什么是向量数据库?工作原理、使用场景与实战指南
随着AI技术席卷各行各业,我们正在经历一场前所未有的技术变革。大语言模型、生成式AI和语义搜索等应用场景的爆发,让数据处理效率成为了决定应用成败的关键因素。这些应用都有一个共同点:它们高度依赖向量嵌入(Vector Embeddings)——一种携带语义信息的数据表示形式。
问题来了:传统的标量数据库在处理这种高维向量数据时力不从心。这时候,向量数据库(Vector Database)应运而生,专门为存储、索引和检索向量嵌入而设计。
向量数据库的核心定义
简单来说,向量数据库是一种专门用于索引和存储向量嵌入的数据库系统,它能够实现快速检索和相似性搜索,同时支持CRUD操作、元数据过滤、水平扩展和无服务器部署等能力。
为什么我们需要专门的向量数据库?因为嵌入向量由AI模型生成,具有多个属性或特征,这些特征代表了数据的不同维度,对于理解模式、关系和底层结构至关重要。传统数据库擅长处理字符串、数字等标量数据,但面对成百上千维的向量数据时,查询效率和语义理解能力都存在明显短板。
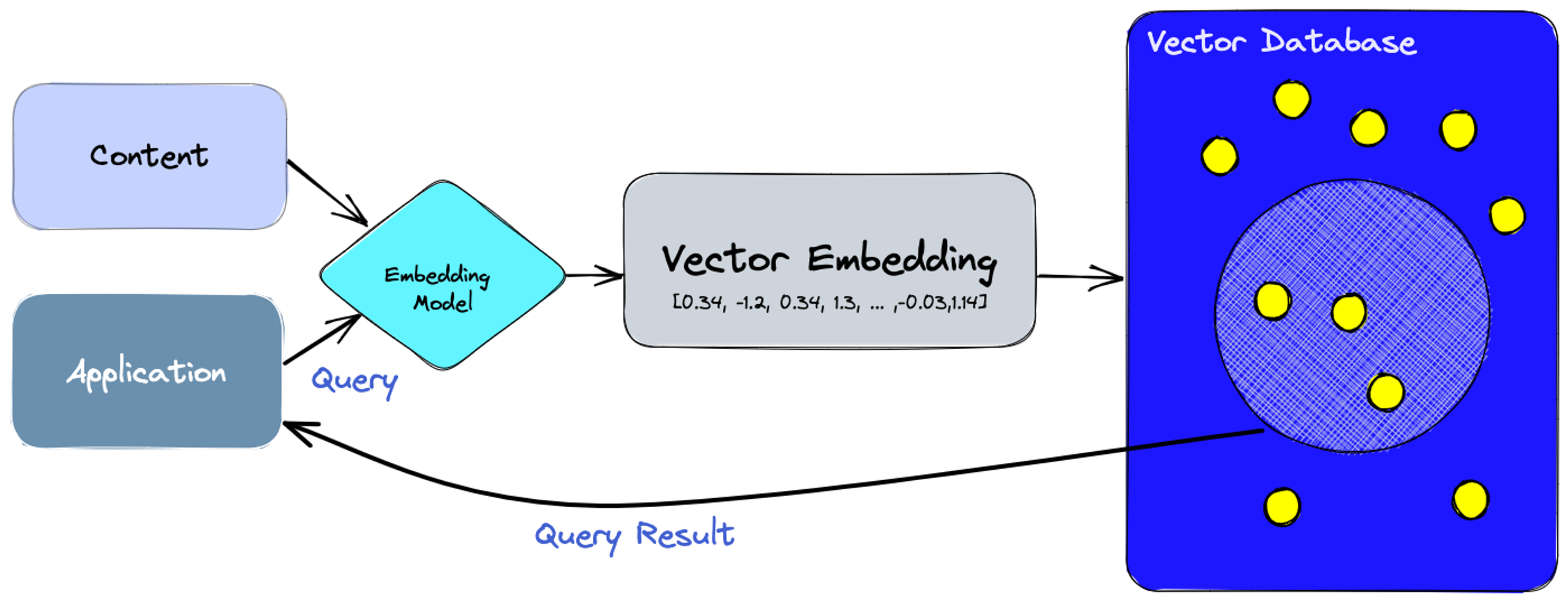
向量数据库在AI应用中的工作流程通常是这样的:
1. 使用嵌入模型将文本、图片等内容转换为向量
2. 将向量存入向量数据库,同时保留与原始内容的关联引用
3. 当用户发起查询时,同样使用嵌入模型将查询转换为向量
4. 在数据库中搜索与查询向量最相似的向量
5. 返回与这些向量关联的原始内容
向量数据库 vs 向量索引:关键区别
像FAISS这样的独立向量索引确实能显著提升向量嵌入的搜索和检索效率,但它们缺少数据库应有的核心功能。向量数据库在以下几个关键方面具有明显优势:
数据管理能力
向量数据库提供了插入、删除、更新等标准数据操作接口,使用起来就像操作普通数据库一样自然。而FAISS这类独立索引需要额外开发与存储系统的集成逻辑,维护成本明显更高。
元数据存储与过滤
向量数据库可以为每条向量记录存储关联的元数据,支持在向量相似性搜索的基础上叠加元数据过滤条件,实现更精细的查询控制。这是独立索引无法原生支持的功能。
水平扩展能力
向量数据库从设计之初就考虑了分布式架构,能够随着数据量和用户请求量的增长平滑扩展。独立索引要达到同等规模,通常需要借助Kubernetes等容器编排系统进行定制化部署。无服务器架构的现代向量数据库还能进一步优化成本效率。
实时更新支持
向量数据库通常支持数据的实时更新,新增数据可以在几秒内被检索到。而独立索引在纳入新数据时可能需要完整的重索引过程,既耗时又消耗计算资源。高级向量数据库还能在保持数据新鲜度的同时,通过索引重建来提升性能。
数据备份与集合管理
向量数据库内置数据备份机制,确保数据安全。部分数据库如Pinecone还支持”集合”(Collections)功能,可以选择特定索引进行选择性备份,便于数据迁移和恢复。
生态系统集成
向量数据库可以轻松与ETL管道(如Spark)、分析工具(如Tableau、Segment)和可视化平台(如Grafana)集成,形成完整的数据处理工作流。在AI领域,与LangChain、LlamaIndex、Cohere等主流框架的对接也更加顺畅。
数据安全与访问控制
向量数据库通常内置数据安全特性和访问控制机制,保护敏感信息。命名空间(Namespace)支持的多租户隔离功能,允许用户完全划分索引,甚至在索引内部创建完全隔离的分区。
向量数据库的工作原理
理解传统数据库的工作方式后,向量数据库的差异就很容易理解了。传统数据库存储字符串、数字等标量数据,按行和列组织,查询时通常要求精确匹配。而向量数据库操作的是高维向量,查询目标是找到与目标向量最相似的向量集合。
向量数据库实现这一目标的核心技术是近似最近邻搜索(ANN – Approximate Nearest Neighbor)。它通过组合多种算法来优化搜索效率,这些算法包括:
- 局部敏感哈希(LSH):通过哈希函数将相似向量映射到相同的桶中,快速筛选候选集
- 乘积量化(PQ):将高维向量压缩为紧凑编码,大幅减少存储空间和计算量
- 层次可导航小世界图(HNSW):构建多层图结构,实现对数级别的搜索效率

一个典型的向量数据库查询流程包含三个阶段:
第一步:索引
向量数据库使用PQ、LSH或HNSW等算法对向量进行索引,将向量映射到专为快速搜索优化的数据结构中。这一步直接影响后续查询的性能上限。
第二步:查询
将查询向量与索引中的向量进行比较,使用索引所采用的相似度度量(如余弦相似度、欧氏距离或点积)找出最近的邻居向量。
第三步:后处理
某些场景下,数据库会从原始数据集中检索最终的最近邻结果,并可能使用不同的相似度度量进行重新排序,确保返回结果的准确性和多样性。
由于ANN搜索提供的是近似结果,我们需要在准确率和查询速度之间做出权衡。系统设计得越好,就越能在保持超高查询速度的同时达到接近完美的准确率。
无服务器向量数据库:下一代架构
早期的向量数据库架构在准确性、速度和扩展性方面表现出色,但成本控制一直是痛点。随着AI应用场景对成本效益和弹性扩展的要求越来越高,无服务器向量数据库代表了技术演进的下一步。
第一代向量数据库的痛点
第一代架构存在三个关键问题:
存储与计算耦合:传统架构下,计算资源始终与存储绑定,导致即使没有查询请求也需要持续付费。这对于间歇性访问的应用场景来说是一种浪费。
多租户隔离不足:处理命名空间时,低频访问的命名空间也会产生计算成本,难以实现精细化的成本控制。
数据新鲜度:新数据插入后需要一定时间才能被检索,在需要实时性的场景下这是不可接受的。
几何分区:存储计算分离的关键
无服务器架构通过几何分区算法将索引拆分为多个子索引,使搜索可以集中在特定分区而非整个空间:
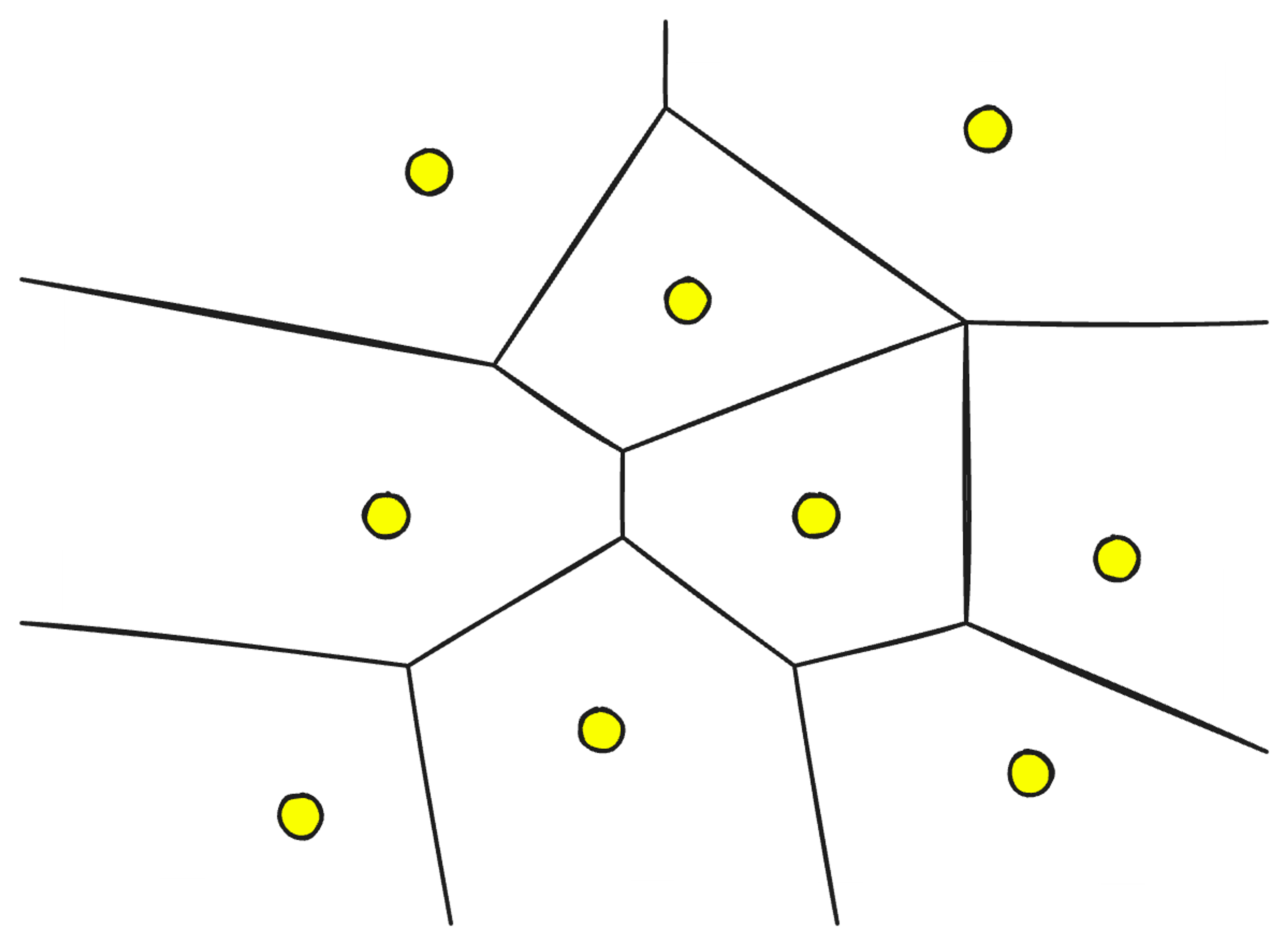
通过这种分区策略,查询的搜索空间被大大缩小。实际使用中,某些分区会被频繁访问,而其他分区则很少被触及,这使得系统能够在计算成本和冷启动时间之间找到最优平衡点。
不过,这种精细的几何分区在索引构建阶段会增加时间复杂度,可能影响数据的实时性。如何在分区效率和索引新鲜度之间取得平衡,是当前无服务器向量数据库持续优化的方向。
向量数据库的典型使用场景
语义搜索与知识增强
在RAG(检索增强生成)架构中,向量数据库存储文档的向量表示。当用户提问时,系统通过语义相似性搜索找到最相关的文档片段,作为上下文提供给大语言模型。这解决了模型知识截止日期的问题,让AI能够回答最新的、专业领域的问题。
推荐系统
将用户偏好和商品特征编码为向量,通过向量相似性计算实现个性化推荐。用户的浏览历史、购买行为等数据可以持续更新到向量数据库中,保证推荐的时效性。
异常检测
在金融风控、网络安全等场景中,正常行为的向量分布具有特定模式。通过计算新数据点与正常模式的向量距离,可以快速识别异常交易或潜在威胁。
图像/音频检索
将图像的视觉特征或音频的声学特征编码为向量,实现”以图搜图”、音乐识别等功能。相比传统的特征匹配方法,向量检索在处理复杂特征时表现更加鲁棒。
实战建议与最佳实践
选择向量数据库时,建议从以下几个维度进行评估:
查询性能与准确率
不同数据库采用的ANN算法和索引结构会影响查询性能。建议在真实数据样本上进行基准测试,关注P99延迟和召回率的平衡点。
扩展性与成本模型
对于预期快速增长的应用,无服务器架构的弹性扩展能力和按需付费模式更具吸引力。但需要评估冷启动延迟是否满足业务需求。
生态系统兼容性
如果你的技术栈中已经包含LangChain、LlamaIndex等框架,选择与这些框架有成熟集成方案的向量数据库可以大幅降低开发成本。
数据安全与合规
处理敏感数据时,需要关注数据库的加密能力、访问控制和审计日志等安全特性,确保满足行业的合规要求。
向量数据库已经成为AI应用栈中不可或缺的组成部分。理解它的工作原理和适用场景,将帮助你在构建智能应用时做出更合理的技术决策。