Java在AI时代的新发力点:深入理解Panama Vector API
现在AI和机器学习火得不行,大家都在找高性能的计算方案。作为Java开发者,我们最关心的就是:Java在数据密集型任务上能不能打?答案是肯定的。今天就聊聊Java平台是怎么通过SIMD和SIMT这些并行计算模型来提升性能的,重点介绍一下Panama Vector API这个利器。
编程模型与执行模型:基础概念回顾
在说Java之前,先把编程模型(Programming Model)和执行模型(Execution Model)这两个概念搞清楚。
编程模型是给开发者看的抽象层,决定了我们怎么写代码来解决实际问题。它规定了数据怎么组织、指令怎么流转、程序各部分怎么交互。常见的编程模型包括:
- 顺序编程(Sequential)
- 并发编程(Concurrent)
- 任务并行和数据并行(Task and Data based Parallelism)
执行模型则是底层的东西,描述程序在硬件上是怎么跑起来的。不同的执行模型对应不同的硬件架构:
- SISD(Single Instruction, Single Data):单处理器CPU,一个指令处理一个数据
- MIMD(Multi Instruction, Multi Data):多处理器CPU,多个核心各干各的
- SIMD(Single Instruction, Multi Data):向量处理器,一条指令处理多个数据
- SIMT(Single Instruction, Multiple Threads):GPU的玩法,万千线程同时执行同一指令但处理不同数据
对于机器学习这种数据密集型任务,SIMD和SIMD和SIMT特别重要,因为它们能充分挖掘数据级并行的潜力。

图1:SIMD执行模型
SIMD:一条指令搞定一堆数据
SIMD的核心思想很简单:别一个个处理数据了,一次性处理一批。想象一下你要把两个数组相加,传统做法是一个元素一个元素加,SIMD则可以一次加它8个、16个甚至更多。
现在主流CPU都支持SIMD指令集扩展:
- Intel的SSE(Streaming SIMD Extensions)
- Intel的AVX(Advanced Vector Extensions),支持256位甚至512位向量
HotSpot JIT编译器现在已经能自动识别一些简单的循环并把它们向量化,但有些复杂场景编译器也搞不定,这时候就需要我们手动显式使用Vector API来告诉JIT:”这里我要用SIMD指令,你给我优化到位”。
SIMT:GPU上的大规模并行
SIMT是GPU的看家本领。GPU和CPU不一样,它有成千上万个轻量级核心,每个核心都能跑同一个指令,但处理不同的数据。
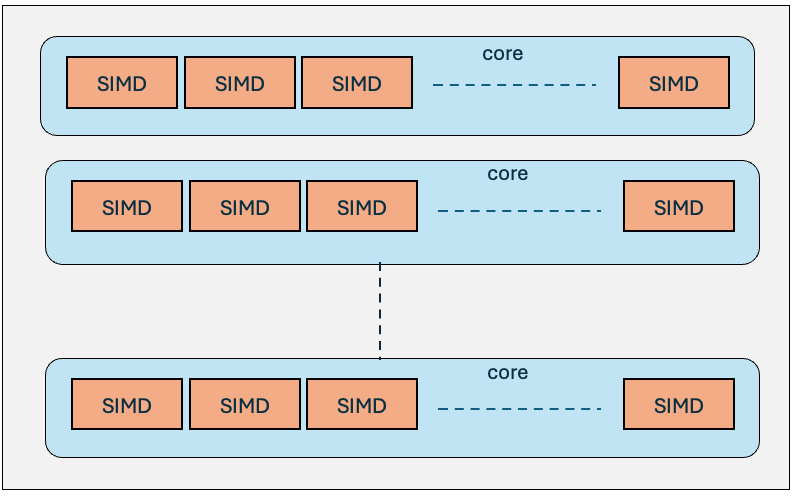
图2:SIMT执行模型
这些线程被分成warp(NVIDIA的叫法)或wavefront(AMD的叫法),每个warp通常包含32或64个线程。同一个warp里的线程步调完全一致,完美利用了数据级并行。GPU就是靠这招在深度学习训练 inference里疯狂加速的。
Java平台的进化:Panama Vector API登场
说完理论,看看Java是怎么应对的。Java平台一直在演进,现在已经原生支持SIMD和SIMT这两种并行执行模型了。
Panama Vector API:手动控制向量计算
HotSpot JIT编译器虽然能自动向量化一些代码,但它的能力有限——对于复杂的业务逻辑,编译器往往爱莫能助。这时候Panama Vector API就派上用场了,它允许我们显式编写利用SIMD指令的代码,确保向量化一定发生。
Vector API的发展历程:
- JEP 338:JDK 16 引入(孵化阶段)
- JEP 414:JDK 17
- JEP 417:JDK 18
- JEP 426:JDK 19
- JEP 438:JDK 20
- JEP 448:JDK 21
- JEP 460:JDK 22
- JEP 469:JDK 23 正式作为孵化API可用
这个API的核心目标很明确:让Java开发者能直接写出利用SIMD硬件能力的向量计算代码,而且不用关心底层是什么硬件——API会自动映射到对应平台的向量指令。
Vector API核心概念
先介绍几个关键概念:
Vector<E>:表示一个向量,E是对应的原始类型,比如byte、int、float等。
Shape(形状):定义了向量的大小(以位为单位),决定了它怎么映射到硬件寄存器。API支持64、128、256、512位的向量形状。一个512位的向量,一次可以处理16个float(512/32=16)或64个byte。
VectorSpecies:定义向量的形状和元素类型。比如IntVector.SPECIES_128表示128位的int向量,能存4个int;FloatVector.SPECIES_256表示256位的float向量,能存8个float。SPECIES_PREFERRED更方便,让Java运行时自动选择当前平台最优的向量形状。
实战:使用Vector API进行数组加法
光说不练假把式,上代码!下面是用Vector API实现两个float数组相加的例子:
import jdk.incubator.vector.*;
import java.util.random.RandomGenerator;
public class VectorizedArrayAddition {
// 动态选择当前硬件最优的向量形状
private static final VectorSpecies SPECIES = FloatVector.SPECIES_PREFERRED;
public static void main(String[] args) {
// 用向量长度作为数组大小的基数,确保能完整分成若干个向量
int size = 4 * SPECIES.length();
// 创建两个float数组
float[] arrayA = new float[size];
float[] arrayB = new float[size];
// 填充随机值
RandomGenerator random = RandomGenerator.getDefault();
for (int i = 0; i < size; i++) {
arrayA[i] = random.nextFloat();
arrayB[i] = random.nextFloat();
}
// 存放结果的数组
float[] result = new float[size];
// 使用Vector API进行向量化加法
// loopBound方法计算循环上界,确保每次迭代处理一个完整的向量
for (int i = 0; i < SPECIES.loopBound(size); i += SPECIES.length()) {
// 从数组中加载一批数据到向量
FloatVector va = FloatVector.fromArray(SPECIES, arrayA, i);
FloatVector vb = FloatVector.fromArray(SPECIES, arrayB, i);
// 向量加法:一次性处理多个元素
FloatVector resultVector = va.add(vb);
// 把结果写回数组
resultVector.intoArray(result, i);
}
// 打印结果
System.out.println("Array A: ");
printArray(arrayA);
System.out.println("Array B: ");
printArray(arrayB);
System.out.println("Result (A + B): ");
printArray(result);
}
// 辅助方法:打印数组
private static void printArray(float[] array) {
for (float value : array) {
System.out.printf("%.4f ", value);
}
System.out.println();
}
}运行结果:
Array A:
0.6924 0.6437 0.9361 0.2659 0.6657 0.4424 0.0379 0.3453 0.8392 0.7864 0.0278 0.2217 0.9544 0.6193 0.1928 0.7600 0.6806 0.2778 0.0493 0.6851 0.3882 0.5876 0.9141 0.0223 0.5135 0.6466 0.6999 0.9271 0.9980 0.3014 0.4377 0.4131
Array B:
0.5600 0.2392 0.7359 0.8160 0.3339 0.4383 0.0610 0.7196 0.8142 0.8749 0.0792 0.7448 0.7568 0.3504 0.3881 0.7346 0.5700 0.3781 0.5894 0.2028 0.4706 0.4465 0.4807 0.6917 0.4530 0.2824 0.2955 0.4308 0.1491 0.9397 0.8949 0.9658
Result (A + B):
1.2524 0.8829 1.6720 1.0819 0.9996 0.8807 0.0989 1.0649 1.6534 1.6612 0.1070 0.9666 1.7112 0.9697 0.5809 1.4947 1.2506 0.6559 0.6387 0.8879 0.8588 1.0341 1.3948 0.7140 0.9665 0.9289 0.9954 1.3579 1.1472 1.2411 1.3325 1.3789代码解读
来拆解一下这个例子里的关键点:
第一,使用SPECIES_PREFERRED是个明智的选择。它会让JVM在运行时根据CPU特性自动选择最优的向量宽度——如果CPU支持AVX-512,那就用512位;如果只支持AVX2,那就用256位。代码一次编写,到处高效运行。
第二,SPECIES.loopBound(size)这个方法很贴心。它帮我们计算循环边界,确保每次迭代刚好处理一个完整向量的数据,避免边界处理麻烦。
第三,FloatVector.fromArray()和intoArray()这对方法负责在Java数组和向量之间搬运数据。注意这里的”一批”是多少元素——取决于SPECIES的长度,可能是4个、8个或16个float。
第四,向量加法va.add(vb)是真正的SIMD操作。一个add指令下去,8个或16个float加法同时完成,这就是性能提升的来源。
实际应用场景
Vector API特别适合这些场景:
- 机器学习推理:矩阵乘法、向量运算、激活函数计算
- 图像处理:像素级操作、卷积运算、滤波器
- 数据分析:大规模数值计算、统计运算
- 金融计算:风险评估、期权定价模型
如果你在写Java版的神经网络前向传播代码,或者处理百万级数据点的统计分析,Vector API绝对值得一试。它比手写循环快,比JNI调用C/C++库省心,而且性能差距已经很小了。
总结
Java平台正在AI和高性能计算领域持续发力。Panama Vector API让我们开发者能直接控制SIMD向量指令,不用再看编译器脸色。对于数据密集型的应用来说,这是个巨大的性能提升机会。
建议感兴趣的朋友可以先用JDK 23+试试水,体验一下SPECIES_PREFERRED的自动适配能力。如果你在做机器学习相关项目,不妨考虑把核心计算逻辑用Vector API重写一下,感受一下SIMD带来的性能飞跃。