做AI应用开发的朋友们应该都深有体会:传统数据库在处理语义搜索、相似度匹配这些场景时真的很吃力。你有没有遇到过这种情况——用户搜”苹果”,结果只返回水果相关的,完全不包含手机品牌?这背后的问题在于,传统数据库做的是关键词匹配,而不是语义理解。
今天这篇文章我们来聊聊怎么用Spring AI结合向量数据库解决这个痛点。我会从基础概念讲起,再到实战代码,手把手教你搭建一个完整的AI应用框架。
什么是向量数据
在深入向量数据库之前,我们先搞清楚什么是向量数据。
简单来说,向量数据就是用一串数字来表示复杂信息的形式。举个例子,我们可以用一个300维的向量来表示”苹果”这个词,这个向量包含了”苹果”在语义空间中的位置信息。在这种表示方式下,语义相近的词在向量空间中也会靠得更近。
这种表示方法叫做词嵌入(Word Embedding),像Word2Vec、GloVe这些技术都是干这个的。文本可以转成向量,图片、音频同样可以。AI模型本质上就是在处理和理解这些高维向量数据。
那向量数据库和传统数据库有啥区别?传统数据库存的是结构化的行和列,查询靠的是精确匹配或者SQL条件。而向量数据库专门为存储和检索向量数据优化,支持的是相似度搜索——找出和查询向量最”像”的结果。
向量数据库的工作原理
向量数据库的核心流程可以拆成三步:
第一步:数据存储
原始数据(文本、图片等)经过AI模型处理后,转换成固定维度的向量,然后存入向量数据库。这个转换过程就是所谓的”向量化”或”Embedding”。
第二步:查询向量化
当用户发起查询时,系统先把查询文本也转成向量。比如用户搜”水果手机”,这个词会被转成一个向量,这个向量代表了用户想要表达的意思。
第三步:相似度计算
数据库在所有存储的向量中,找出和查询向量最相似的那一批。相似度的计算方式有几种:
- 欧几里得距离:两点之间的直线距离,越小越相似
- 余弦相似度:计算两个向量夹角的余弦值,越接近1越相似
- 曼哈顿距离:各维度差值绝对值之和
选择哪种度量方式取决于具体业务场景。余弦相似度在文本语义搜索中用得比较多,因为它更关注向量的方向而不是模长。
向量数据库与AI的关系
为什么向量数据库在AI领域这么火?主要有这几个原因:
检索增强生成(RAG)
RAG是现在AI应用的主流架构。简单说就是:AI回答问题之前,先去向量数据库里检索相关资料,然后把检索结果和用户问题一起喂给大模型。这样做的好处是既能利用大模型的生成能力,又能结合企业私有的知识库,解决模型”幻觉”问题。
高效处理高维数据
AI处理的数据维度都很高——一张图片可能有几千维,一段文本可能有几百维。传统数据库在处理这种数据时性能会急剧下降,而向量数据库专门为此优化,支持百万级向量的快速检索。
实时响应
很多AI应用场景对响应时间要求很高,比如智能客服、实时推荐。向量数据库能在毫秒级完成相似度搜索,满足实时性需求。
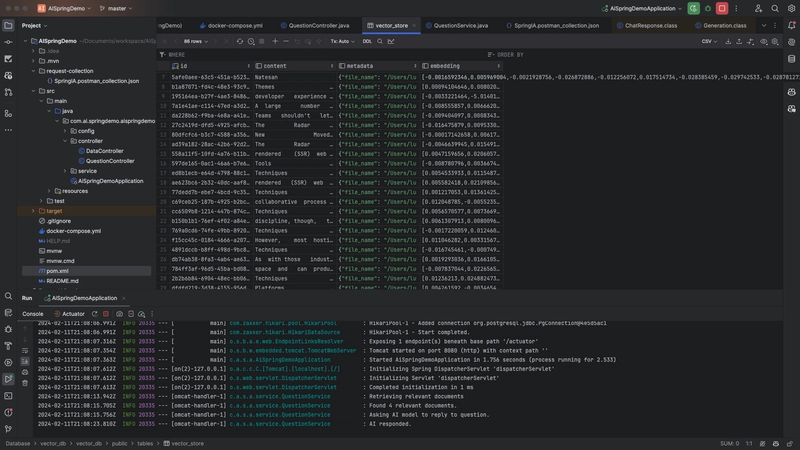
Spring AI项目简介
Spring AI是Spring生态为AI应用开发推出的框架,目标就是让开发者能像用Spring Data JPA那样自然地使用AI能力,而不用关心底层实现细节。它提供了统一的抽象层,你可以轻松切换不同的AI模型供应商。
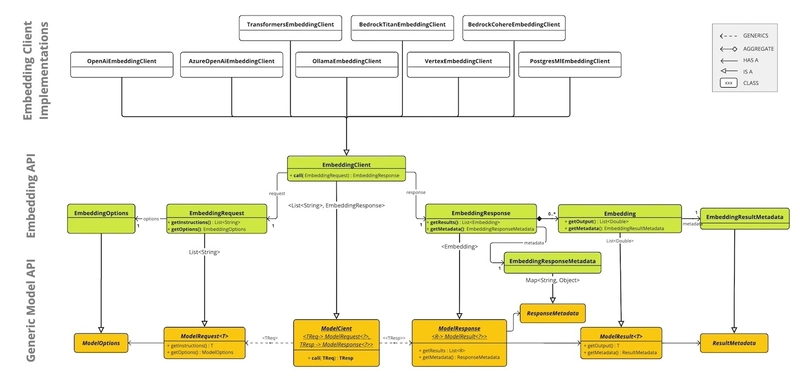
Embedding:文本向量化的桥梁
EmbeddingClient是Spring AI中处理向量化的核心接口。它的作用很简单:把文本转成向量。接口设计得很简洁,核心方法就两个:
// 单文本向量化
List<Float> embed(String text);
// 文档向量化
List<Float> embed(Document document);
这个接口的设计有两个亮点:
可移植性:接口抽象做得好,你可以无缝切换OpenAI、Azure、百度文心等不同提供商的Embedding模型,业务代码基本不用改。这和Spring Data的思想一脉相承。
易用性:屏蔽了向量化的复杂性,开发者不用自己去调模型API、处理返回结果,专注业务逻辑就行。
Prompts:与大模型对话的方式
Prompt就是你和AI模型对话的方式。同样一个问题,不同的Prompt得到的答案可能天差地别。在Spring AI中,Prompt的处理方式借鉴了Spring MVC的思想——把Prompt看作是一个”视图模板”,里面可以包含占位符,运行时动态填充。
这就好比我们在Spring MVC里用Thymeleaf模板渲染视图,PromptTemplate的使用方式几乎一模一样:
PromptTemplate template = new PromptTemplate(
"请根据以下上下文回答问题:\n上下文:{context}\n问题:{question}"
);
Prompt prompt = template.create(
Map.of("context", retrievedContext, "question", userQuestion)
);
Spring AI现在的定位有点像早期的JDBC——提供了基础能力,但上层还有很大的抽象空间。未来可能会出现类似JdbcTemplate、Spring Data Repository这样的高级封装,比如ChatEngine、Agent这些概念,让AI编程变得更加声明式。
ETL管道:数据处理的流水线
在RAG架构中,ETL(Extract抽取、Transform转换、Load加载)管道是数据处理的核心环节。它的职责是把原始数据(PDF、Word、网页等)处理成向量,然后存入向量数据库。
典型的处理流程是这样的:从数据源抽取原始文本,对文本进行清洗和分块,向量化后存入数据库。这个过程看似简单,但有很多细节需要注意:
- 文本分块的大小要适中,太大可能包含无关信息,太小可能丢失上下文
- 分块之间要有适当的重叠,保证语义连贯
- 要保留文档的元数据(标题、来源、页码等),方便后续追溯
实战项目:Spring AI + pgvector
说了这么多理论,我们来动手实操。我会用一个完整的示例演示怎么搭建Spring AI应用,整合pgvector向量数据库。
环境准备:启动pgvector
pgvector是PostgreSQL的向量数据库插件,能在熟悉的PostgreSQL上提供向量检索能力,非常适合已经在用Postgres的团队。
version: '3.7'
services:
postgres:
image: ankane/pgvector:v0.5.0
restart: always
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=admin
- POSTGRES_DB=vector_db
- PGPASSWORD=admin
ports:
- '5433:5432'
healthcheck:
test: "pg_isready -U postgres -d vector_db"
interval: 2s
timeout: 20s
retries: 10
启动命令:
docker compose up -d
项目配置:添加依赖
Spring AI的版本更新很快,这里用0.8.0-SNAPSHOT版本。需要引入OpenAI集成、PDF读取器和pgvector存储的依赖:
<spring-ai.version>0.8.0-SNAPSHOT</spring-ai.version>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store</artifactId>
<version>${spring-ai.version}</version>
</dependency>
application.yml中配置OpenAI的API Key:
spring:
ai:
openai:
api-key: ${OPENAI_API_KEY}
embedding:
client:
enabled: true
datasource:
url: jdbc:postgresql://localhost:5433/vector_db
username: postgres
password: admin
核心代码实现
整个应用分成两部分:数据处理和问答处理。
数据处理模块负责把PDF文档转成向量存入数据库:
@Service
public class DocumentIngestionService {
private final EmbeddingClient embeddingClient;
private final PgVectorStore vectorStore;
private final PdfDocumentReader pdfReader;
public void processDocument(Path pdfPath) {
// 1. 读取PDF文档
List<Document> documents = pdfReader.getDocuments(pdfPath);
// 2. 向量化并存储
documents.forEach(doc -> {
List<Float> embedding = embeddingClient.embed(doc);
doc.setEmbedding(embedding);
vectorStore.add(List.of(doc));
});
}
}
问答模块负责检索相关文档并生成回答:
@Service
public class QAService {
private final EmbeddingClient embeddingClient;
private final PgVectorStore vectorStore;
private final ChatClient chatClient;
public String ask(String question) {
// 1. 把问题转成向量
List<Float> questionEmbedding = embeddingClient.embed(question);
// 2. 检索相似文档
List<Document> relevantDocs = vectorStore.similaritySearch(questionEmbedding);
// 3. 构建Prompt
String context = relevantDocs.stream()
.map(Document::getContent)
.collect(Collectors.joining("\n\n"));
PromptTemplate template = new PromptTemplate(
"根据以下上下文回答问题。如果上下文中没有相关信息,请说明你不知道。\n\n上下文:{context}\n\n问题:{question}"
);
Prompt prompt = template.create(Map.of(
"context", context,
"question", question
));
// 4. 调用大模型生成回答
return chatClient.call(prompt).getResult().getOutput().getContent();
}
}
运行应用
配置好OpenAI的API Key后,直接运行:
mvn spring-boot:run -Dspring-boot.run.profiles=openai
总结
这篇文章我们聊了向量数据库的核心概念、Spring AI的关键组件,以及一个完整的实战示例。几点关键信息回顾一下:
- 向量数据库解决的是语义层面的相似度检索问题,是AI应用的基础设施
- Spring AI提供了统一的抽象层,让AI能力集成变得简单
- pgvector作为PostgreSQL的扩展,部署成本低,适合快速上手
- RAG架构是目前AI应用的主流模式,核心就是向量检索+大模型生成